20241009_딥러닝으로 이미지 학습시키기_02_모델 만들고 학습시키기
in 파이썬
의류 이미지를 보고 카테고리를 분류하는 모델만들고 학습시키기 (Flatten Layer, Model Summary)
- 옷 사진을 보고 카테고리를 분류하는 모델을 만들고 학습시키려고 한다.(이게 바지인지 셔츠인지 ..)
- 결과는 이런식으로 나오게 할 예정
- 티셔츠일 확률 x % , 트라우저일 확률 y% …. 부츠일 확률 z%
0. 카테고리 선언
- class_names = [‘T-shirt/top’,’Trouser’,’Pullover’,’Dress’,’Coat’,’Sandal’,’Shirt’,’Sneaker’,’Bag’,’Ankel boot’]
1. 모델 만들기
- 기존에 불러온 테스트용 구글 데이터셋을 가지고 모델을 만든다.
- 이 때 모델이 잘 만들어졌나 보기 위해서 summary 메서드를 활용할 수 있다.
- 단 summary를 활용하기 위해서는 keras.layers.Dense 설정 시 input_shape를 지정해줘야 한다.(학습시킬때는 keras가 알아서 해주기 때문에 선언해주지 않아도 상관 없음)
model = tf.keras.Sequential([ ## summary를 보고싶으면 input_shape=(28,28) 집어넣어야함 (그냥 컴파일할꺼면 알아서 해주는데 미리 보고싶으면 모양을 설정해줘야함)
tf.keras.layers.Dense(128, input_shape=(28,28), activation="relu"), ## , activation="relu" : 음수는 다 0으로 만드는 활성함수
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Flatten(), ## 3D Dense layer를 1D로 나열해주는 레이어
tf.keras.layers.Dense(10, activation="softmax") ## class_name배열의 각각의 항목에 해당하는 확률 예측하기, softmax : 0~1 카테고리 예측/ sigmoid : 0~1 압축 왼쪽오른쪽,합격 불합격 등
])
1.1 model.summary() - 모델이 잘 만들어졌나 확인해보기
- 내가 만든 layers 구성을 학습 전에 미리 볼 수 있게 도와주는 메서드이다.
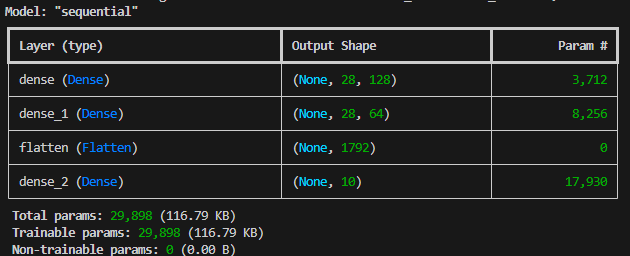
- 다음과 같이 모델을 확인할 수 있다.
2. 컴파일
- 손실함수는 ‘sparse_categorical_crossentropy’ 를 사용한다.
- sparse_categorical_crossentropy : 카테고리 예측문제에 사용하는 손실함수
- 정답데이터(이 글에서는 trainY)가 원핫인코딩이 되어있을때는 categorical_crossentropy를 사용해준다.
- 이때는 마지막 layer는 softmax 활성함수를 사용해야한다.
- 원핫인코딩 : 정답을 컴퓨터가 이해할 수 있도록 변환해주는것 정답이 [1,2,3,4] 이걸 [[0,0,0,1],[0,0,1,0]…] 이런식으로 표현이 되어있으면 원 핫 인코딩이다.
model.compile(loss="sparse_categorical_crossentropy",optimizer="adam",metrics=['accuracy'])
3. 학습
- X,Y데이터를 5회반복해서 학습시킨다.
Epoch 1/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 2s 731us/step - accuracy: 0.7423 - loss: 2.4241
Epoch 2/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 712us/step - accuracy: 0.8347 - loss: 0.4744
Epoch 3/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 705us/step - accuracy: 0.8477 - loss: 0.4331
Epoch 4/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 701us/step - accuracy: 0.8574 - loss: 0.4005
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 700us/step - accuracy: 0.8659 - loss: 0.3817
model.fit(trainX,tranY,epochs=5)
4. 전체 소스
import tensorflow as tf
import matplotlib.pyplot as plt ## 이미지를 볼 수 있는 파이썬 라이브러리 , pip install matplotlib를 통해 설치
## 데이터 셋 가져오기
## 텐서플로우에서 제공하는 기본 데이터 셋 중 하나로 이미지 데이터랑 정답 데이터가 들어있음.(실행 시 구글에서 다운받아짐)
(trainX,tranY),(testX,testY) = tf.keras.datasets.fashion_mnist.load_data() ## 이 데이터셋을 활용할때만 사용하는 선언방식으로 신경쓸필요 없음
class_names = ['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankel boot']
## 1. 모델만들기
model = tf.keras.Sequential([ ## summary를 보고싶으면 input_shape=(28,28) 집어넣어야함 (그냥 컴파일할꺼면 알아서 해주는데 미리 보고싶으면 모양을 설정해줘야함)
tf.keras.layers.Dense(128, input_shape=(28,28), activation="relu"), ## , activation="relu" : 음수는 다 0으로 만드는 활성함수
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Flatten(), ## 3D Dense layer를 1D로 나열해주는 레이어
tf.keras.layers.Dense(10, activation="softmax") ## class_name배열의 각각의 항목에 해당하는 확률 예측하기, softmax : 0~1 카테고리 예측/ sigmoid : 0~1 압축 왼쪽오른쪽,합격 불합격 등
])
## 1.1 모델이 잘 만들어졌나 확인해보기
model.summary() ## param# : 학습가능한 w,b 갯수
## 2. 컴파일
model.compile(loss="sparse_categorical_crossentropy",optimizer="adam",metrics=['accuracy'])
## 3. 학습
model.fit(trainX,tranY,epochs=5)
5. Flatten Layer의 문제점과 대체제 (Convolutional layer)
- 모델을 만들 때 Flatten layer는 다차원 배열을 1차원으로 압축시켜주는 역할을 하는데, 원본 데이터가 조금만 바껴도 이 1차원 데이터는 완전히 달라지게 된다.
- 그래서 응용력이 전혀 없는 모델이라는 소리가 된다.
- 해결책은 Convolutional layer인데,
- 이 layer는 한 이미지에서 중요한 정보를 추려서 서로 다른 복사본을 20장 만든다.
- 그곳엔 이미지의 중요한 featuer(특성)이 담겨있음. (이게 자동차의 창문이다, 문이다 , 바퀴다 ..등등)
5.1 컨볼루션레이어 적용해보기
- 컨볼루션 레이어를 사용하기 위해 reshape해주기
trainX = trainX.reshape((trainX.shape[0],28,28,1)) ## shape를 28x28(픽셀)에서 28x28,1(흑백이기때문에 1, rgb를 모두사용하면 3이됨)로 reshape
testX = testX.reshape((testX.shape[0],28,28,1))
- 모델을 만들 때 다음 순으로 레이어를 추가해줘야 한다.
- 컨볼루션레이어 - 풀링 - 플래튼 (1차원변환) - 덴스
model = tf.keras.Sequential([ ## summary를 보고싶으면 input_shape=(28,28) 집어넣어야함 (그냥 컴파일할꺼면 알아서 해주는데 미리 보고싶으면 모양을 설정해줘야함)
tf.keras.layers.Conv2D(32,(3,3),padding="same",activation="relu", input_shape=(28,28,1)), ## 컨볼루션 레이어 추가 / 첫번째 매개변수 : N개의 복사본만들기 / 2번째 매개변수 : 픽셀 사이즈 X x Y / 4번째 매개변수 : relu사용이유 > 숫자는 음수가 없기 때문에 / 5번째 매개변수 :
tf.keras.layers.MaxPooling2D((2,2)), ## 풀링레이어 사용
# tf.keras.layers.Dense(128, input_shape=(28,28), activation="relu"), ## , activation="relu" : 음수는 다 0으로 만드는 활성함수
tf.keras.layers.Flatten(), ## 3D Dense layer를 1D로 나열해주는 레이어
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax") ## class_name배열의 각각의 항목에 해당하는 확률 예측하기, softmax : 0~1 카테고리 예측/ sigmoid : 0~1 압축 왼쪽오른쪽,합격 불합격 등
])
6. 모델평가하기
- evaluate 메서드를 사용하면 모델을 평가할 수 있다. // model.evaluate(testX,testY)
6-1. overfitting 현상
- epochs를 진행하면서 오른 정확도와 모델평가 정확도가 다른 이유는 overfitting현상때문임 epochs를 반복 시행하면서 케이스별 답을 외워버리기때문에 그렇다네
- 대안으로 학습마다 모델평가를 진행하는 방법이 있는데 다음과 같이 바꿔주면 된다.
- model.fit(trainX,tranY,validation_data=(testX,testY), epochs=5)
