20241101_개_고양이_구분_AI_만들기
in 파이썬
개_고양이_구분_AI_만들기
1. 데이터 준비와 개발환경 셋팅
1) 데이터 다운로드
데이터 다운로드 : https://www.kaggle.com/competitions/dogs-vs-cats-redux-kernels-edition/
google colab 에서 Kaggle 데이터 다운받기 ``` import os os.environ[‘KAGGLE_CONFIG_DIR’] = ‘/content/’ # <– Kaggle My Profile>Settings>API>Create New Token 눌러서 json 다운로드 !kaggle competitions download -c dogs-vs-cats-redux-kernels-edition
다운로드 완료 후 압축풀기
!unzip -q dogs-vs-cats-redux-kernels-edition.zip -d . !unzip -q train.zip -d .
- 로컬에서 데이터 다운로드 : https://www.kaggle.com/competitions/dogs-vs-cats-redux-kernels-edition/data
## 2) 데이터 전처리
- 압축해제한 이미지를 다음 폴더로 생성 후 이동시킨다
- \train\cat~~~ => \dataset\cat
- \train\dog~~~ => \dataset\dog
``` py
import os
import shutil
for i in os.listdir('/content/train/'):
if 'cat' in i:
shutil.copyfile('/content/train/'+i,'/content/dataset/cat/'+i) ## 1:어떤파일 2: 어떤경로로
if 'dog' in i:
shutil.copyfile('/content/train/'+i,'/content/dataset/dog/'+i) ## 1:어떤파일 2: 어떤경로로
데이터셋만들기
- keras를 이용해서 손쉽게 데이터셋을 만들 수 있다. dataset 하위 폴더들에 있는 데이터를 가지고 데이터셋을 만들자
import tensorflow as tf
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
'/content/dataset/',
image_size=(64,64),
batch_size=32, # 그냥학습하지 않고 batch_size갯수만큼씩 계산하게 함
subset='training', # 벨리데이션 관련설정1
validation_split=0.2, # 벨리데이션 관련설정2 / 0~1 , 20%만큼을 데이터셋으로 사용하겠다
seed = 1234 # 아무값
)
## 벨리데이션을 위해서는 아래와 같이 객체를 하나 더 선언해야한다.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
'/content/dataset/',
image_size=(64,64),
batch_size=32, # 그냥학습하지 않고 batch_size갯수만큼씩 계산하게 함
subset='training',
validation_split=0.2, # 0~1 , 20%만큼을 데이터셋으로 사용하겠다
seed = 1234 # 아무값(배치에 활용)
)
print(train_ds)
## 2개로 분류가 잘 되었다.
#Found 25000 files belonging to 2 classes.
#Using 20000 files for training.
# 전처리하기 (학습 시간을 단축시키기 위함)
## 0~255 값을 0~1로 압축시키기
def 전처리함수(i,정답):
i = tf.cast(i/255.0,tf.float32)
return i,정답
train_ds = train_ds.map(전처리함수) # map(함수)를 모든 값에 적용해주기
val_ds = val_ds.map(전처리함수)
2. 학습시키기
- 기존에 모델 학습에 사용했던 방법을 재사용한다
- 개냐 고양이냐는 binary_crossentropy 로스함수를 사용하고, 얘는 레이어 마지막 활성함수로 sigmoid를 필요로 한다.
- 추가로 overfitting을 방지하기 위해 Dropout를 사용했다. dropout은 이전 레이어에서 입력한 %만큼 제거해버리는 레이어다.
## 1. 모델만들기
## 컨볼루션레이어 - 풀링 - 플래튼 (1차원변환) - 덴스
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32,(3,3),padding="same",activation="relu", input_shape=(64,64,3)), ## 컨볼루션 레이어 추가 #컬러 사진이라 inputshpae 마지막 매개변수는 3
tf.keras.layers.MaxPooling2D((2,2)), ## 풀링레이어 사용
#정확도를 높히기 위해 컨볼루션레이어를 1회 더 반복
tf.keras.layers.Conv2D(64,(3,3),padding="same",activation="relu", input_shape=(64,64,3)), ## 컨볼루션 레이어 추가 #컬러 사진이라 inputshpae 마지막 매개변수는 3
tf.keras.layers.MaxPooling2D((2,2)), ## 풀링레이어 사용
tf.keras.layers.Dropout(0,2), ## overfitting 를 방지하는 레이어 (윗 레이어의 20%를 제거해줌)
tf.keras.layers.Flatten(), ## 3D Dense layer를 1D로 나열해주는 레이어
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid") ## binary_crossentropy -> sigmoid가 필요함
])
## 1.1 모델이 잘 만들어졌나 확인해보기
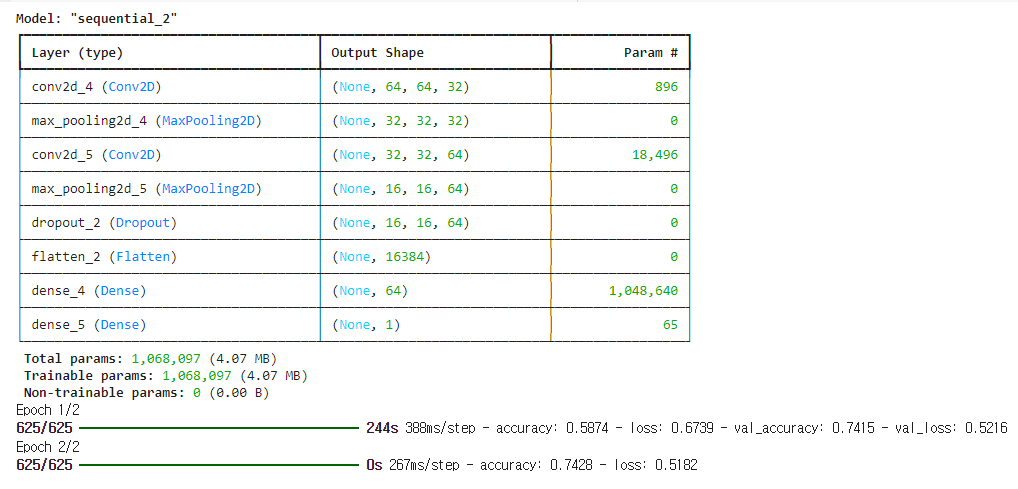
model.summary() ## param# : 학습가능한 w,b 갯수
## 2. 컴파일
model.compile(loss="binary_crossentropy",optimizer="adam",metrics=['accuracy'])
## 3. 학습
model.fit(train_ds,validation_data=val_ds, epochs=2)
3. 결과
- 강의에서는 데이터의 질이 문제로 정확도가 낮은 것 같다고 함.
4. 정확도를 높히는 방법 = 이미지 증강
- 이미지 증강이란 원본이미지를 조금씩 변형시켜 (확대,뒤틀기,회전,방향바꾸기등) 해당 이미지들도 딥러닝을 시키는것을 말하는데 이를 통해 정확도를 높힐 수 있음
4.1 이미지 증강 방법
- 1) 이미지 처리 프로그램을 통해 원본이미지 + 변경이미지를 만들어서 학습을 돌린다. (개노가다같음)
- 2) 모델에 이미지를 넣기 전에(레이어 맨앞이겠지?) 이미지 증강 epoch마다 이미지를 랜덤하게 뒤틀 수 있음
tf.keras.layers.RandomFlip('horizontal', input_shape=(28,28,1)), # 이미지증강1. 뒤집기 tf.keras.layers.RandomRotation(0.1, input_shape=(28,28,1)), # 이미지증강2. 회전 tf.keras.layers.RandomZoom(0.1, input_shape=(28,28,1)), # 이미지증강3. 줌
